Review: Amazon SageMaker plays catch-up
With Studio, Autopilot, and other additions, Amazon SageMaker is now competitive with the machine learning environments available in other clouds






Contributor, InfoWorld |

-
Amazon SageMaker
When I reviewed Amazon SageMaker in 2018, I noted that it was a highly scalable machine learning and deep learning service that supports 11 algorithms of its own, plus any others you supply. Hyperparameter optimization was still in preview, and you needed to do your own ETL and feature engineering.
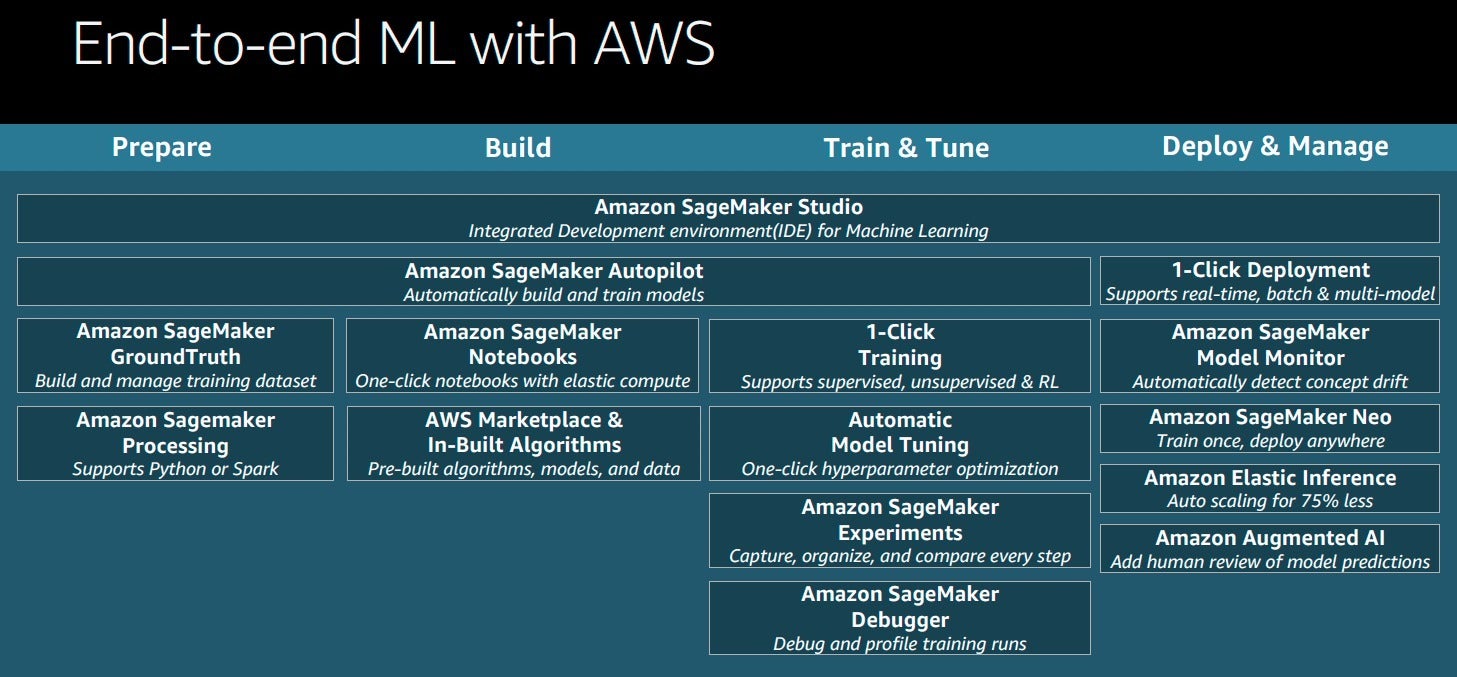
Since then, the scope of SageMaker has expanded, augmenting the core notebooks with IDEs (SageMaker Studio) and automated machine learning (SageMaker Autopilot) and adding a bunch of important services to the overall ecosystem, as shown in the diagram below. This ecosystem supports machine learning from preparation through model building, training, and tuning to deployment and management — in other words, end to end.
 IDG
IDG
Amazon SageMaker Studio improves on the older SageMaker notebooks, and a number of new services have enhanced the SageMaker ecosystem to support end-to-end machine learning.
What’s new in SageMaker?
What’s new? Given that I last looked at SageMaker just after it was released, the list is rather long, but let’s start with the most visible services.
- SageMaker Studio, an IDE based on JupyterLab
- SageMaker Autopilot, which automatically builds and trains up to 50 feature-engineered models that can be examined in SageMaker Studio
- SageMaker Ground Truth, which helps to build and manage training datasets
- SageMaker Notebooks now offer elastic compute and single-click sharing
- SageMaker Experiments, which helps developers visualize and compare machine learning model iterations, training parameters, and outcomes
- SageMaker Debugger, which provides real-time monitoring for machine learning models to improve predictive accuracy, reduce training times, and facilitate greater explainability
- SageMaker Model Monitor, which detects concept drift to discover when the performance of a model running in production begins to deviate from the original trained model
Other notable improvements include the optional use of spot instances for notebooks to reduce the cost; a new P3dn.24xl instance type that includes eight V100 GPUs; an AWS-optimized TensorFlow framework, which achieves close to linear scalability when training multiple types of neural networks; Amazon Elastic Inference, which can dramatically decrease inference costs; AWS Inferentia, which is a high-performance machine learning inference chip; and new algorithms, both built-in to SageMaker and available in the AWS Marketplace. In addition, SageMaker Neo compiles deep learning models to run on edge computing devices, and SageMaker RL (not shown on the diagram) provides a managed reinforcement learning service.
SageMaker Studio
JupyterLab is the next-generation, web-based user interface for Project Jupyter. SageMaker Studio uses JupyterLab as the basis for an IDE that’s a unified online machine learning and deep learning workstation with collaboration features, experiment management, Git integration, and automatic model generation.
The screenshot below shows how to install the SageMaker examples into a SageMaker Studio instance, using a terminal tab and the Git command line. The instructions for doing this are in the README for this example, which is kind of a Catch-22. You can read them by browsing to the Getting Started example on GitHub, or by cloning the repository to your own machine and reading it there.
 IDG
IDG
SageMaker Studio showing the folder view at the left, and a terminal at the right. In the terminal, we have run a Git command line to populate the instance with Amazon’s SageMaker examples from GitHub.
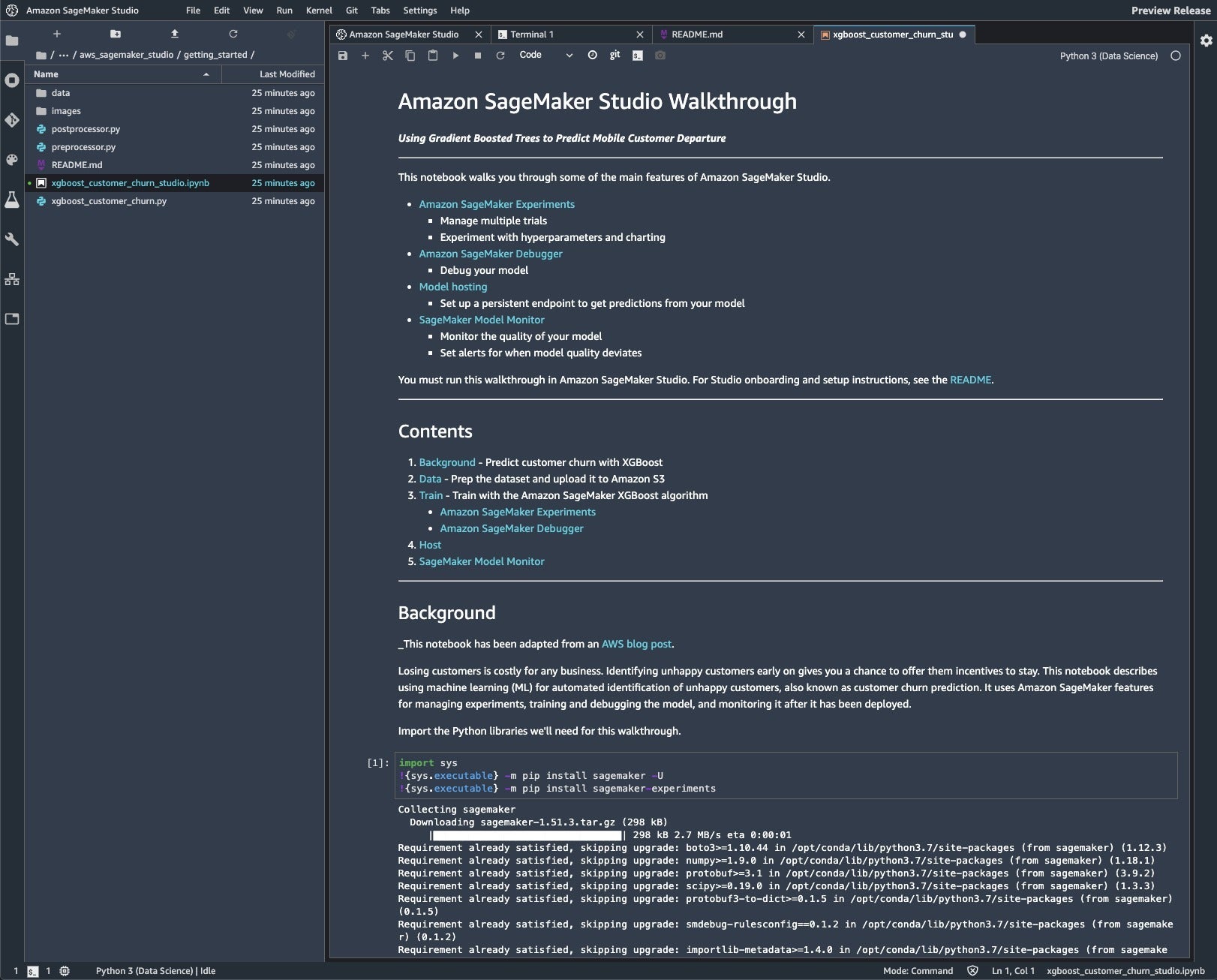
Amazon’s Getting Started example contains a notebook called xgboost_customer_churn_studio.ipynb, which was adapted from a blog post about predicting customer churn. As Jupyter notebooks go, it has lots of explanations, as you can see in the screenshots below.
 IDG
IDG
Amazon SageMaker Studio Walkthrough. This example touches on four of the major features of SageMaker Studio: Experiments, the debugger, model hosting, and the model monitor. It starts with prepping the data, then training, then hosting and monitoring.
 IDG
IDG
In steps 4 and 5 of the XGBoost notebook we take a quick look at the training data and upload the files to Amazon S3. If the required bucket doesn’t exist, we create it.
 IDG
IDG
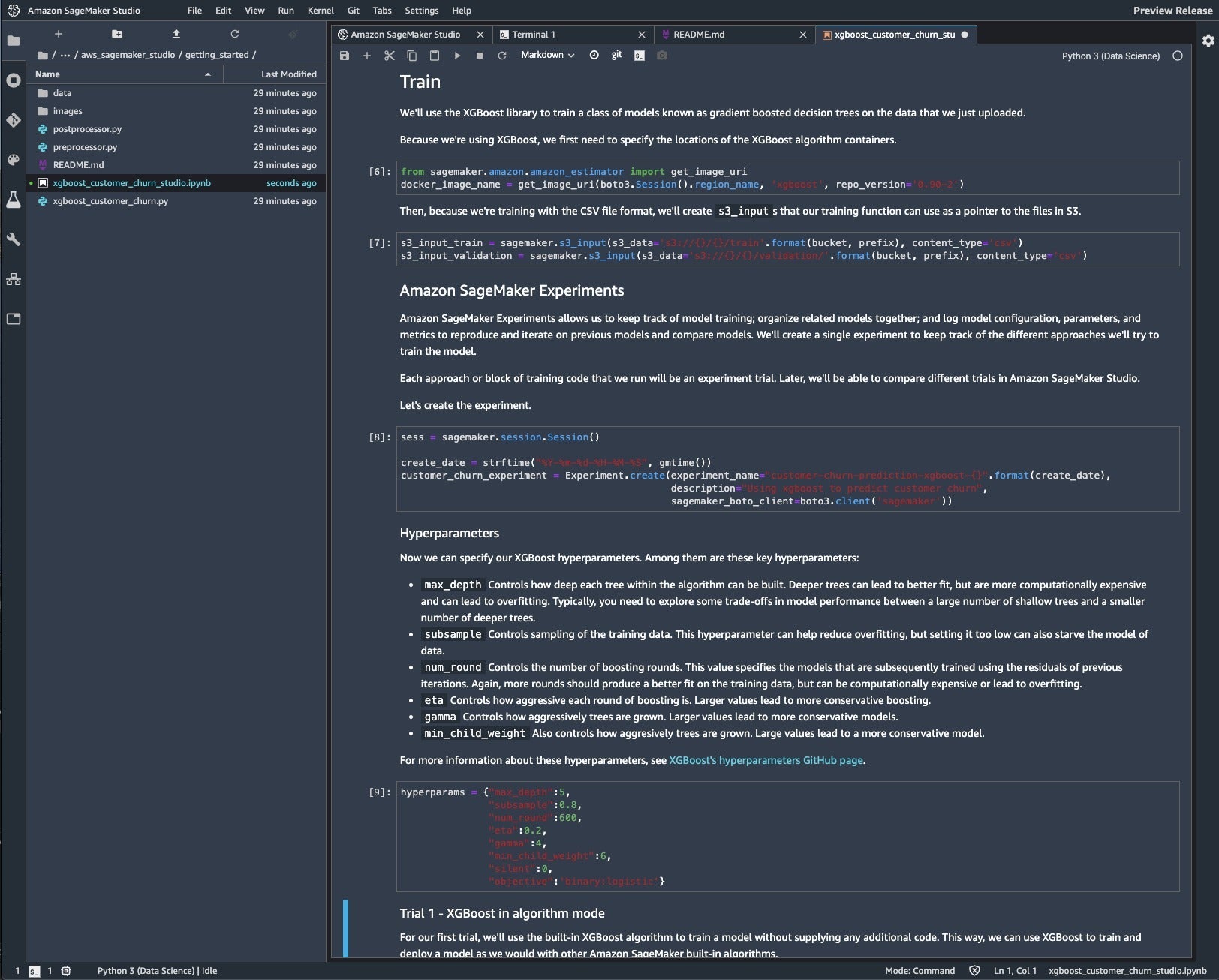
In steps 6 through 9 we set up the Experiment and define the hyperparameters to use for the XGBoost training. We start with the built-in XGBoost algorithm.
 IDG
IDG
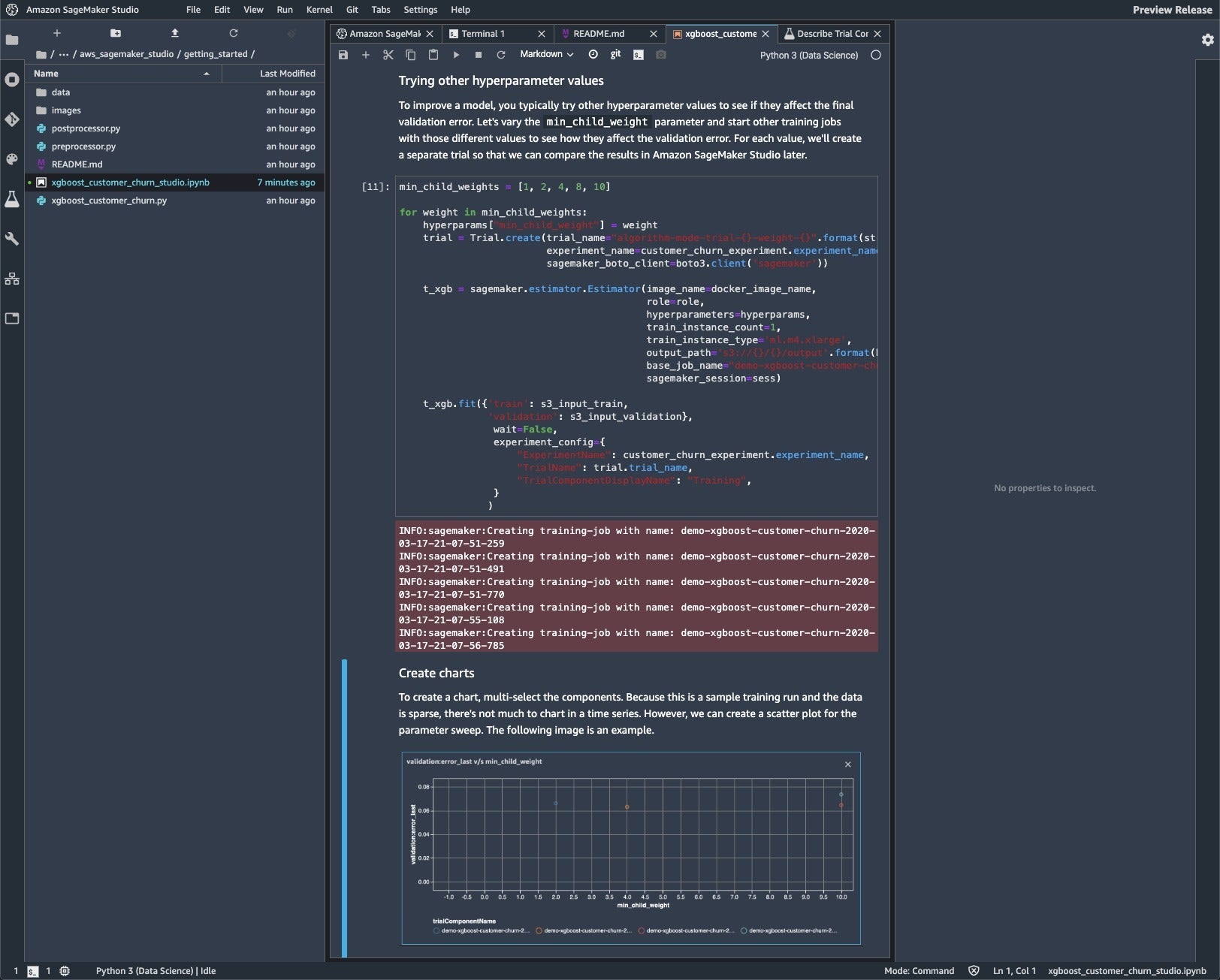
In step 10 we create a trial and run the first training. Note that we’re using one ml.m4.xlarge instance for the training.
 IDG
IDG
In step 11 we run five more trainings, for different values of the min_child_weight hyperparameter. The chart at the bottom is a static example, but I was able to follow the instructions to create my own chart from the components of this trial.
The example goes on to run an additional training with an external XGBoost algorithm modified to save debugging information to Amazon S3 and to invoke three debugging rules. This is in what’s called framework mode, meaning that it’s not a built-in algorithm.
When the trainings are all done, you can compare the results in the Experiments tab.
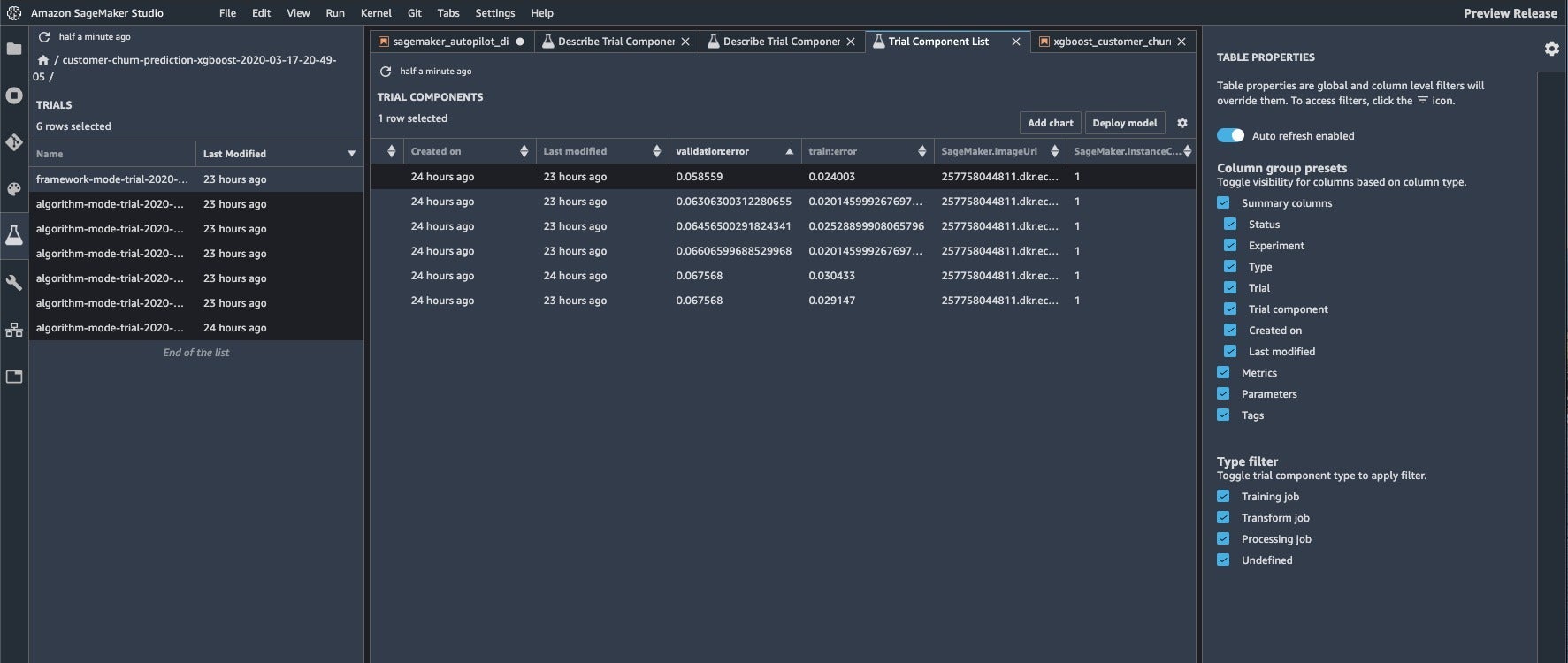 IDG
IDG
Here we are comparing the results of six trials in algorithm mode in the Experiments tab. The results are ordered by validation error in this view.
The example then hosts the model using its deploy method and tests the deployed endpoint using its predict method. Finally, it creates a baselining job with the training dataset and a scheduled monitoring job that reports any constraint violations.
By the way, XGBoost is only one of the many algorithms built into SageMaker. A full list is shown in the table below — and you can always create your own model.
 IDG
IDG
Amazon SageMaker’s built-in algorithms. You can always use other algorithms in “framework” mode by supplying the code.
SageMaker Autopilot
Suppose you don’t know how to do feature engineering and you aren’t very familiar with the different algorithms available for the various machine learning tasks. You can still use SageMaker — just let it run on autopilot. SageMaker Autopilot is capable of handling datasets up to 5 GB.
In the screenshot below we are running the Direct Marketing with Amazon SageMaker Autopilot example. It starts by downloading the data, unzipping it, uploading it to an S3 bucket, and launching an Autopilot job by calling the create_auto_ml_job API. Then we track the progress of the job as it analyzes the data, does feature engineering, and does model tuning, as shown below.
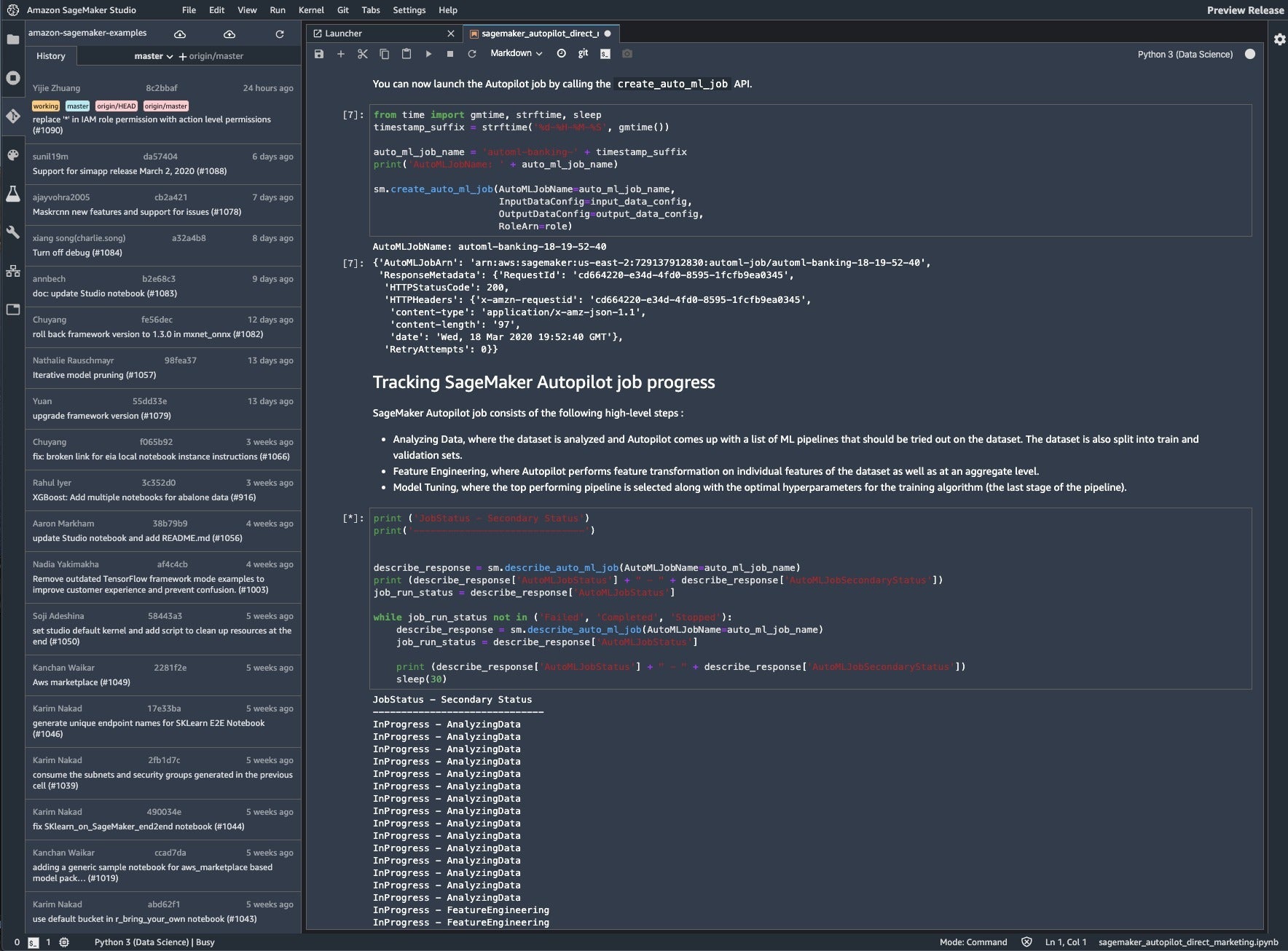 IDG
IDG
At right, we see a SageMaker Autopilot job running in SageMaker Studio. It completed in about four hours. At left, we see SageMaker Studio’s Git support.
The example then picks the best model, uses it to create and host an endpoint, and runs a transform job to add the model predictions to a copy of the test data. Finally, it finds the two notebooks created by the Autopilot job.
There is a user interface to the Autopilot results, although it’s not obvious. If you right-click on the automl experiment you can see all the trials with their objective values, as shown below.
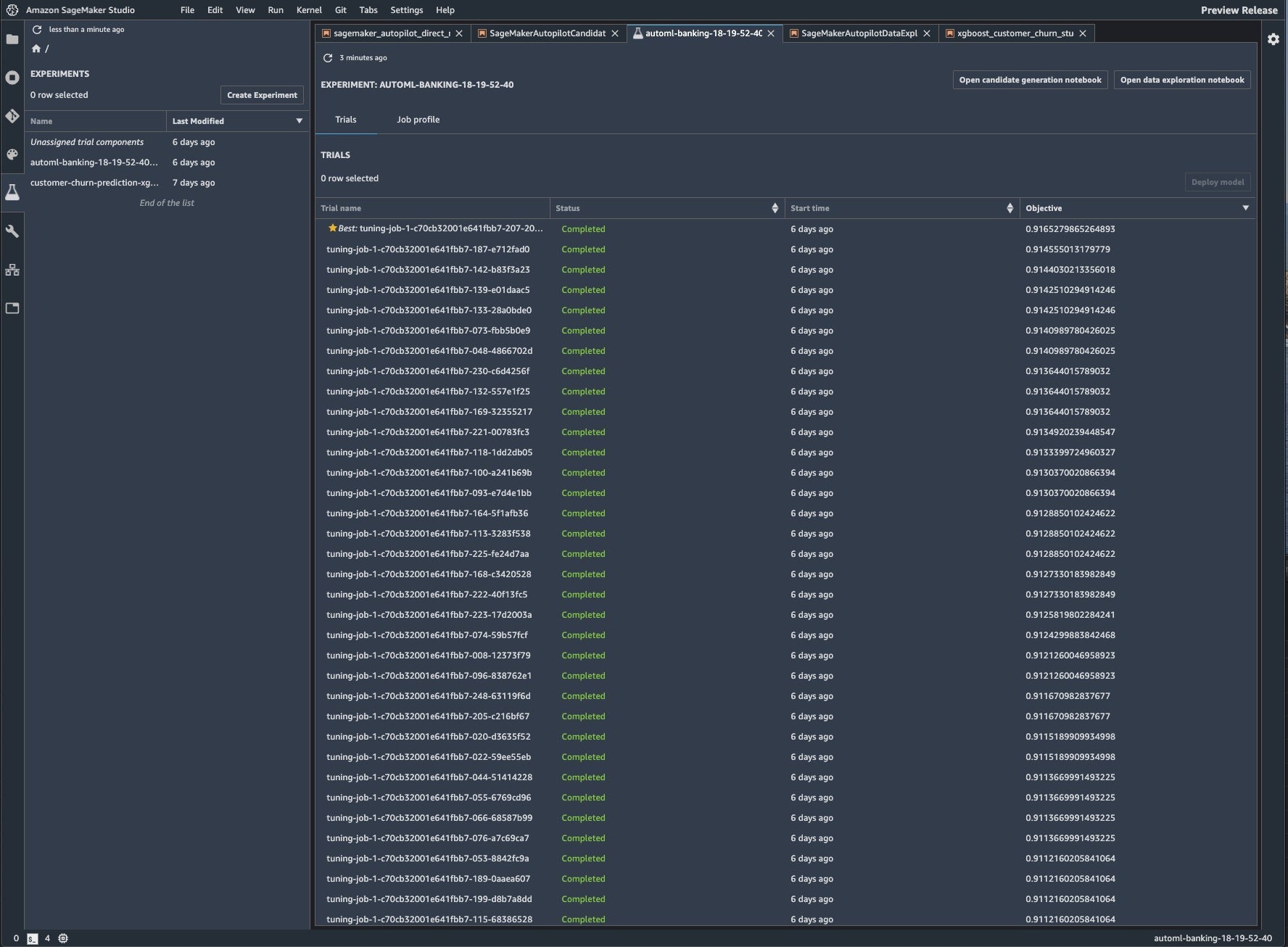 IDG
IDG
Click on the Objective column title to sort the results and bring the best one to the top; click on the buttons at the top right to open the candidate generation and data exploration notebooks.
SageMaker Ground Truth
If you’re lucky, all your data will be labeled, or otherwise annotated, and ready to be used as a training dataset. If not, you can annotate the data manually (the standard joke is that you give the task to your grad students), or you can use a semi-supervised learning process that combines human annotations with automatic annotations. SageMaker Ground Truth is such a labeling process.
As you can see in the diagram below, Ground Truth can be applied to a number of different tasks. With Ground Truth, you can use workers from either Amazon Mechanical Turk, or a vendor company that you choose, or an internal, private workforce along with machine learning to enable you to create a labeled dataset.
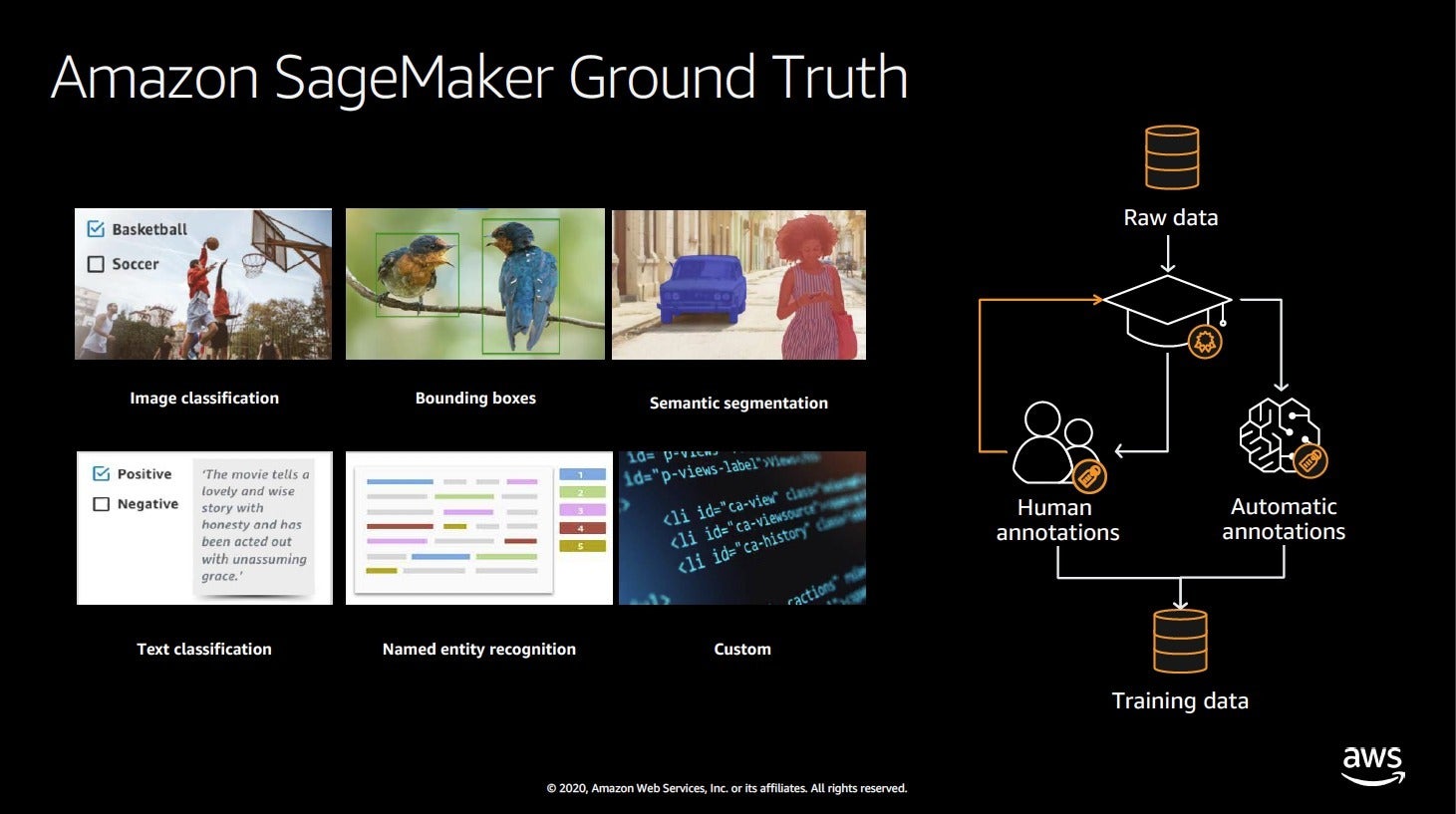 IDG
IDG
Amazon SageMaker Ground Truth combines human annotations with automatic annotations to turn raw data into training data for model building.
Amazon provides seven walkthroughs that demonstrate various ways of using SageMaker Ground Truth.
SageMaker Neo
Until recently, deploying trained models on edge devices — smartphones and IoT devices, for example — has been difficult. There have been specific solutions, such as TensorFlow Lite for TensorFlow models and TensorRT for Nvidia devices, but SageMaker Neo compiles and automatically optimizes TensorFlow, Apache MXNet, PyTorch, ONNX, and XGBoost models for deployment on ARM, Intel, and Nvidia processors as well as Qualcomm, Cadence, and Xilinx devices.
According to AWS, Neo can double the performance of models and shrink them enough to run on edge devices with limited amounts of memory.
SageMaker inference deployment options
In terms of compute, storage, network transfer, etc., deploying models for production inference often accounts for 90 percent of the cost of deep learning, while the training accounts for only 10 percent of the cost. AWS offers many ways to reduce the cost of inference.
One of these is Elastic Inference. AWS says that Elastic Inference can speed up the throughput and decrease the latency of getting real-time inferences from your deep learning models that are deployed as Amazon SageMaker hosted models, but at a fraction of the cost of using a GPU instance for your endpoint. Elastic Inference accelerates inference by allowing you to attach fractional GPUs to any Amazon SageMaker instance.
Elastic Inference is supported in Elastic Inference-enabled versions of TensorFlow, Apache MXNet, and PyTorch. To use any other deep learning framework, export your model by using ONNX, and then import your model into MXNet.
If you need more than the 32 TFLOPS per accelerator you can get from Elastic Inference, you can use EC2 G4 instances, which have Nvidia T4 GPUs, or EC2 Inf1 instances, which have AWS Inferentia custom accelerator chips. If you need the speed of Inferentia chips, you can use the AWS Neuron SDK to compile your deep learning model into a Neuron Executable File Format (NEFF), which is in turn loaded by the Neuron runtime driver to execute inference input requests on the Inferentia chips.
At this point, the Amazon SageMaker Studio preview is good enough to use for end-to-end machine learning and deep learning: data preparation, model training, model deployment, and model monitoring. While the user experience still leaves a few things to be desired, such as better discovery of functionality, Amazon SageMaker is now competitive with the machine learning environments available in other clouds.
—
Cost: $0.0464 to $34.272 per instance hour for compute, depending on number of CPUs and GPUs; SSD storage: $0.14 per GB-month; Data transfer: $0.016 per GB in or out.
Platform: Hosted on Amazon Web Services.
Copyright © 2020 IDG Communications, Inc.