






The thing about clouds is that they can change shape even as you watch them. So it is with the Google Cloud, and the guidance we provided InfoWorld readers two years ago about creating a SQL Server failover cluster instance (FCI) in the Google Cloud no longer reflects best practices.
The guidance provided then still works, but changes in the Google Cloud mean that organizations wanting a cloud-based infrastructure supporting SQL Server at 99.99 percent availability levels now have better, more efficient ways to create SQL Server FCIs. The fundamentals of those new guidelines can be found in Google’s online instructions for configuring a SQL Server FCI.
Google’s current guidance is clear and easy to follow. But organizations serious about 99.99 percent levels of availability should follow these guidelines only up to a point. As outlined in the documentation, the FCI relies on shared storage configured using Microsoft’s Storage Spaces Direct option, and that creates an availability Catch-22.
The issue is this: Microsoft guidelines for Storage Spaces Direct require all the VMs and storage to reside in the same data center, and it’s not clear that an FCI configured in the manner outlined by Google complies with this requirement. The Google documentation directs you to place the VMs in multiple zones within the Google Cloud, and if these zones are not the same data center then you’re creating a Storage Spaces Direct configuration that is unsupported.
The Catch-22 is that if you configure the FCI so that all the VMs are in the same data center, and thus compliant with Storage Spaces Direct guidelines, your FCI does not qualify for Google’s high availability SLA (which requires that at least one VM in the SQL Server FCI reside in a different zone). If the whole data center goes offline (and whole data centers have done so), the entire FCI will also go offline.
Creating compliant failover clusters in the Google Cloud
One way to build a fully supported SQL Server FCI for high availability involves using third party SANless failover clustering software. SANless failover clustering software is purpose-built to create just what the name implies: a storage-agnostic, shared-nothing cluster of servers and storage with automatic failover for application availability. As an HA solution, these clusters are capable of operating across both the LAN and WAN in private, public, and hybrid clouds. These clusters are also extensible, enabling organizations to have a single, universal HA solution across most applications.
Most HA SANless failover clustering software provides a combination of real-time block-level data replication, continuous application monitoring, and configurable failover/failback recovery policies to protect business-critical applications, including those using the Always On Failover Clustering feature in the Standard and Enterprise editions of SQL Server.
Some of the more robust HA SANless failover clustering solutions also offer advanced capabilities, such as ease of configuration and operation with an intuitive graphical user interface, a choice of synchronous or asynchronous replication, WAN optimization to maximize performance, manual switchover of primary and secondary server assignments for planned maintenance, and the ability to perform regular backups without disruption to the application.
How to configure a SQL Server Failover Cluster Instance using SANless cluster technology
The basic Google instructions for creating a simple two-server failover cluster on GCP can be followed without alteration through the first seven steps:
- Set up the VPC Network
- Create and configure the Windows Domain Controller
- Create and cluster the VMs and data disks
- Create the cluster VMs’ network
- Create the file share witness
- Create the internal load balancer
- Create the Windows failover cluster
Note that you can configure FCIs with three or more servers using the same basic process. To ensure you have at least one node in a different data center you will want to locate it in an entirely different region.
Once you have created the FCI (at the end of the seventh step above) you need to interrupt the Google-documented process detailed below in order to create the SANless cluster components that can ensure true 99.99 percent availability (without running the risk of creating an unsupported Storage Spaces Direct configuration that spans data centers).
The guidelines provided here for configuring a SANless failover cluster in the Google Cloud rely on SIOS DataKeeper Cluster Edition. DataKeeper uses block-level replication to ensure that the locally attached storage on each SQL instance remains in sync, even across data centers. It also integrates with Windows Server Failover Clustering through its own storage class resource called a DataKeeper Volume, which takes the place of the physical disk resource. Within the cluster, the DataKeeper volume appears to be a physical disk, but instead of controlling SCSI reservations, it controls the mirror direction, thereby ensuring that only the active server writes to the disk and that the passive servers receive all the changes either synchronously or asynchronously.
Configuring a SANless cluster using SIOS DataKeeper
Note: You should not install SIOS DataKeeper until you have created the basic cluster (per the steps outlined in the Google documentation) because the DataKeeper installation process registers the DataKeeper Volume Resource type in failover clustering. If you installed DataKeeper before creating the basic cluster, simply run the DataKeeper setup application again and choose Repair Installation.
Install and set up the SIOS DataKeeper application
Install and set up SIOS DataKeeper per the instructions sent in the email from SIOS. This is an intuitive process, but documentation is available on the docs.us.sios.com website.
Create the DataKeeper Volume Resource
Step 1: Open the DataKeeper UI and click the “Connect to Server” command in the right-hand Actions pane and connect DataKeeper to each of your cluster nodes. (Note that all screen shots are for illustration only; you should use the node names and IP addresses you used when configuring the FCI.)
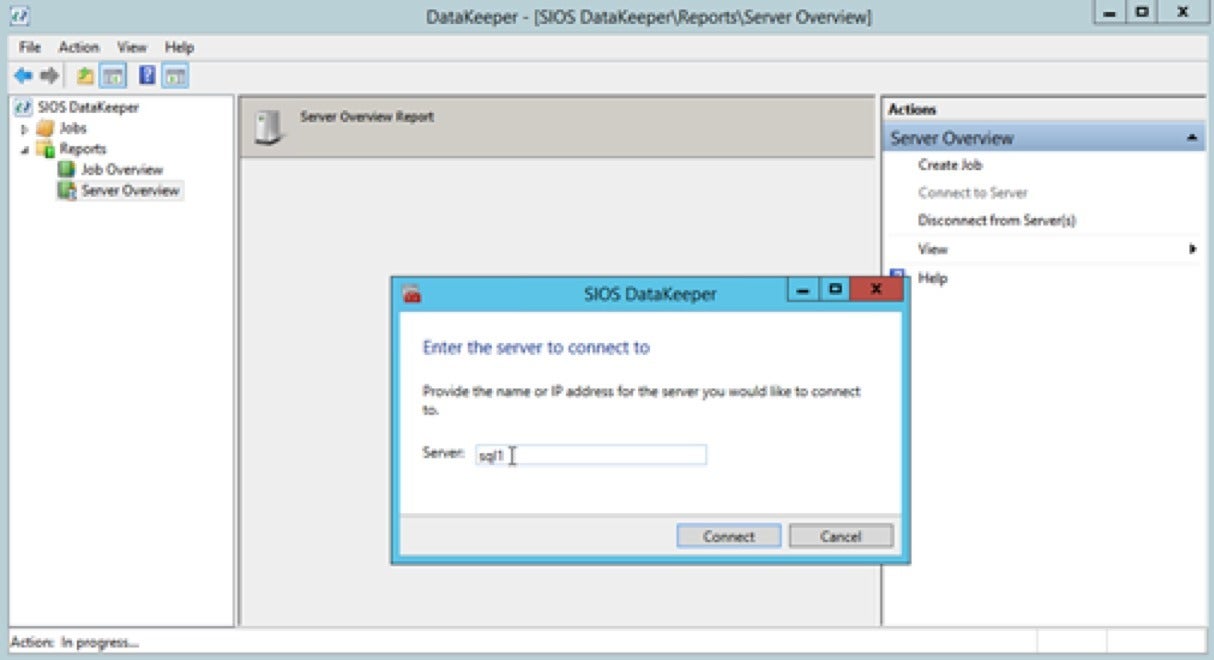 SIOS Technology
SIOS TechnologyEnter each server name in the panel and click Connect. Once you have added all the servers in your cluster, the Server Overview Report should look something like this:
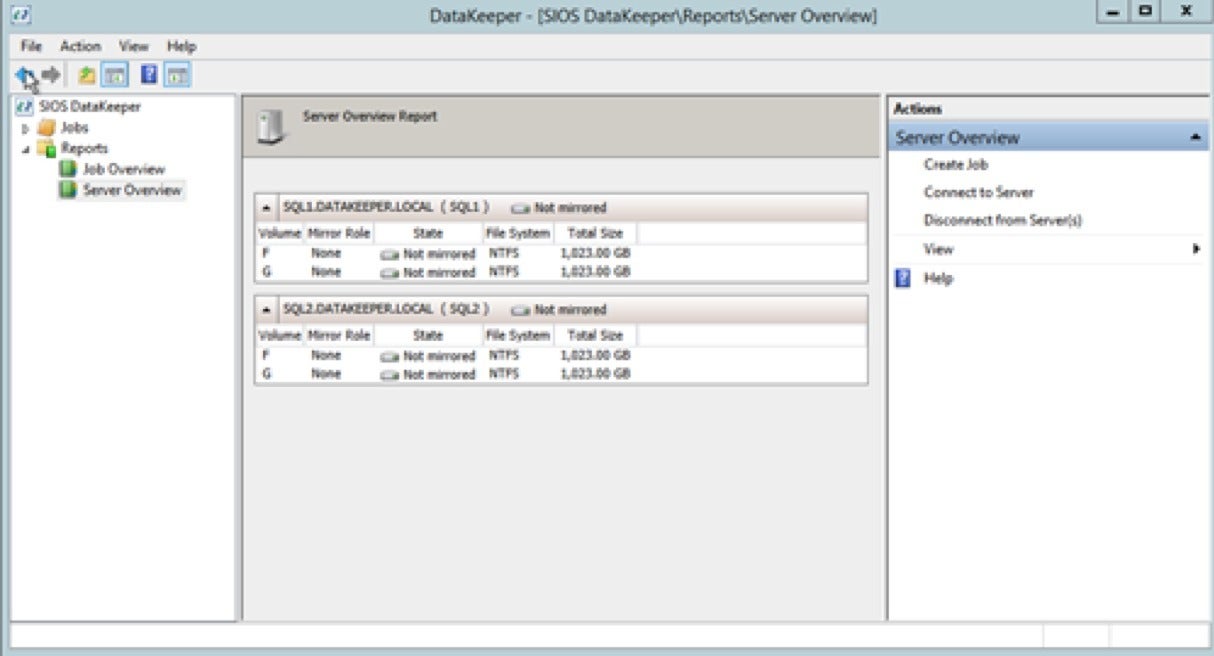 SIOS Technology
SIOS TechnologyStep 2: Click the Create Job command in the right-hand Actions pane. This will create your first mirror disk.
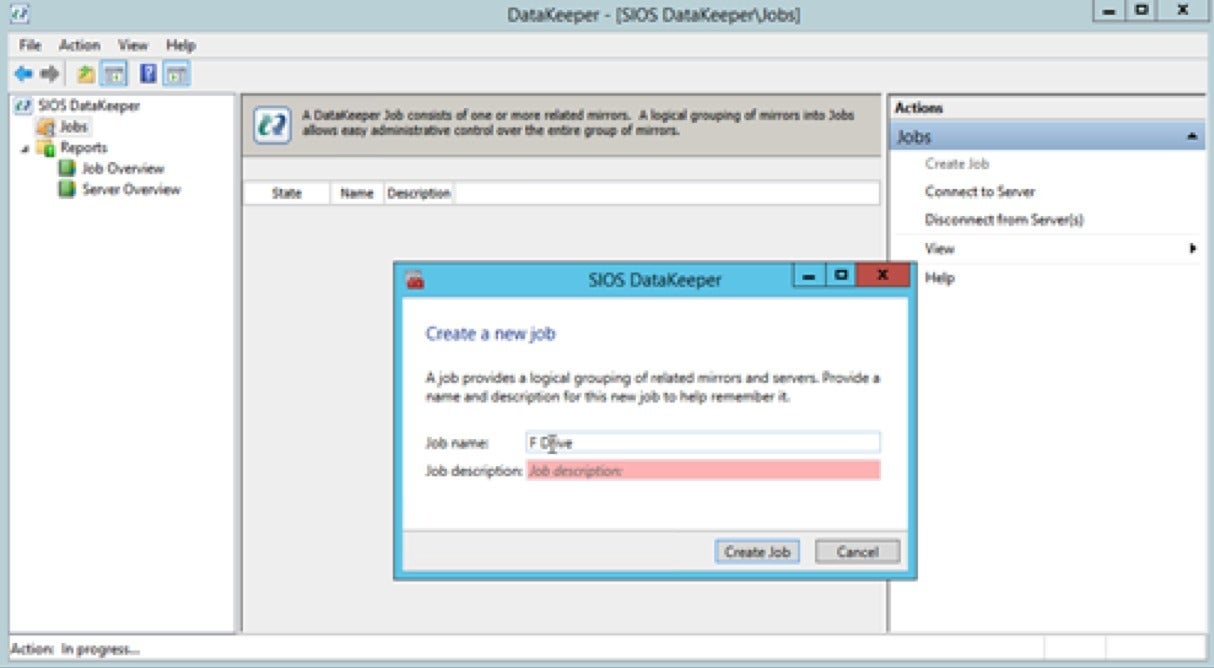 SIOS Technology
SIOS TechnologyType a job name in the field (the job description is optional) and click Create Job. This will cause the New Mirror panel to appear.
 SIOS Technology
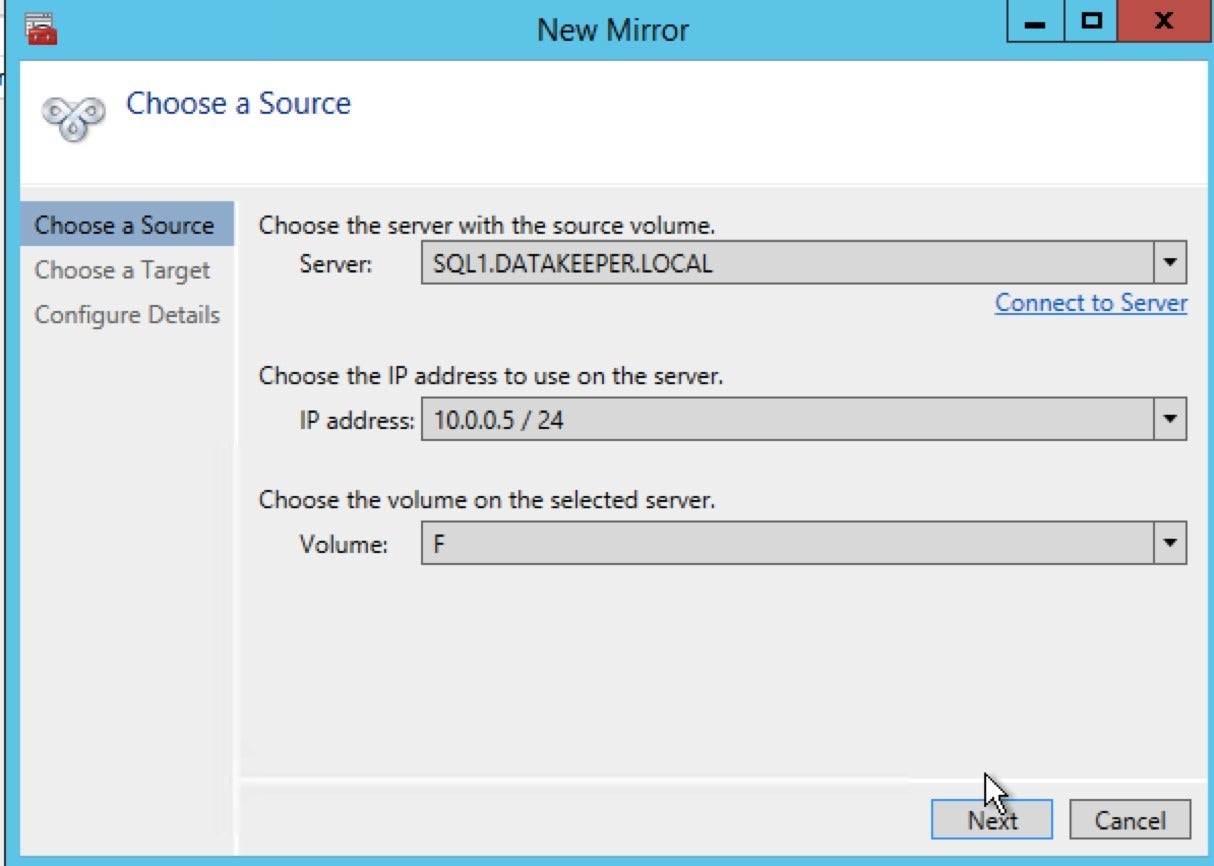
SIOS TechnologyStep 3: Identify your primary SQL Server data source by selecting “Choose a Source” in the left-hand pane of the New Mirror panel.
In the fields below, identify server, IP address, and storage volume associated with the primary SQL Server node in your cluster. Then click Next.
The “Choose a Target” pane of the New Mirror panel appears:
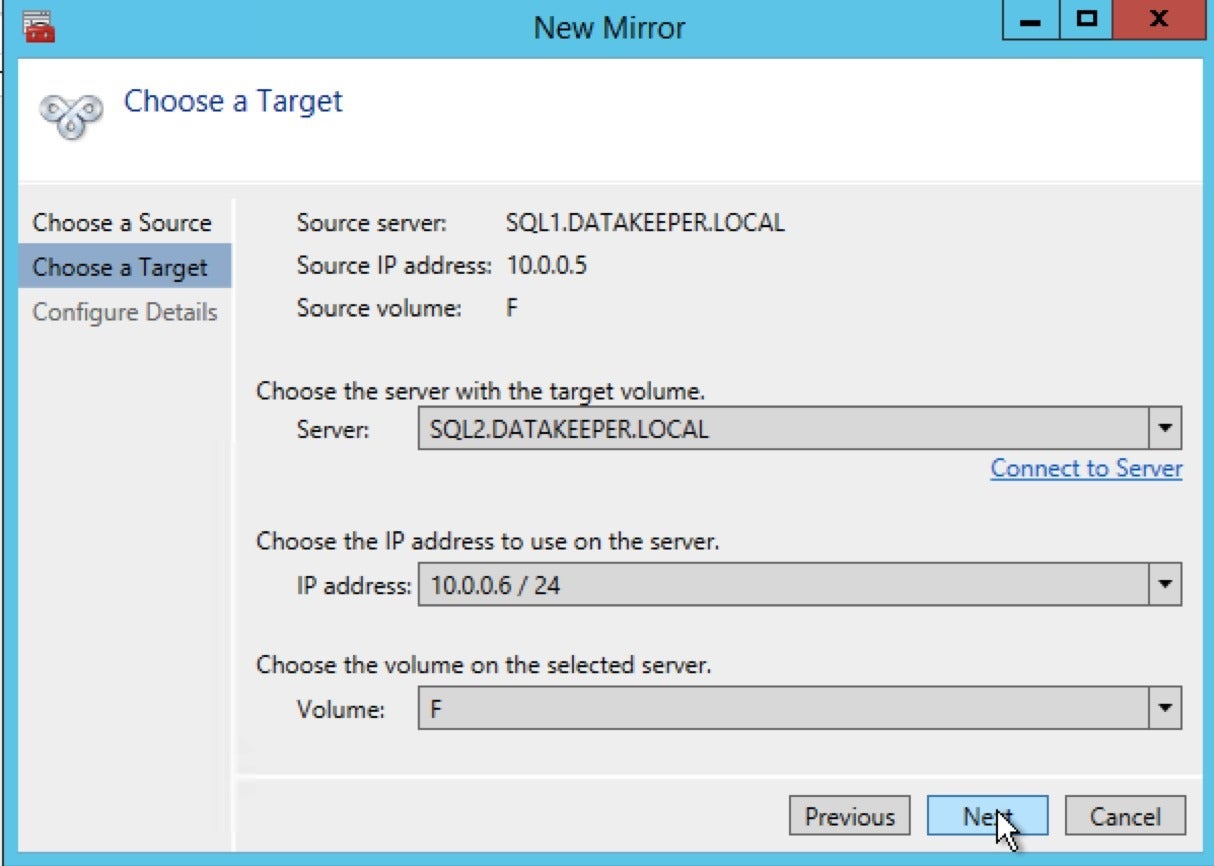 SIOS Technology
SIOS TechnologyHere you should enter the server, IP address, and volume associated with the secondary SQL Server node in your cluster. This will be the target to which DataKeeper replicates all the data from the source volume. After you have added this information, click Next.
The Configure Details pane of the New Mirror panel appears:
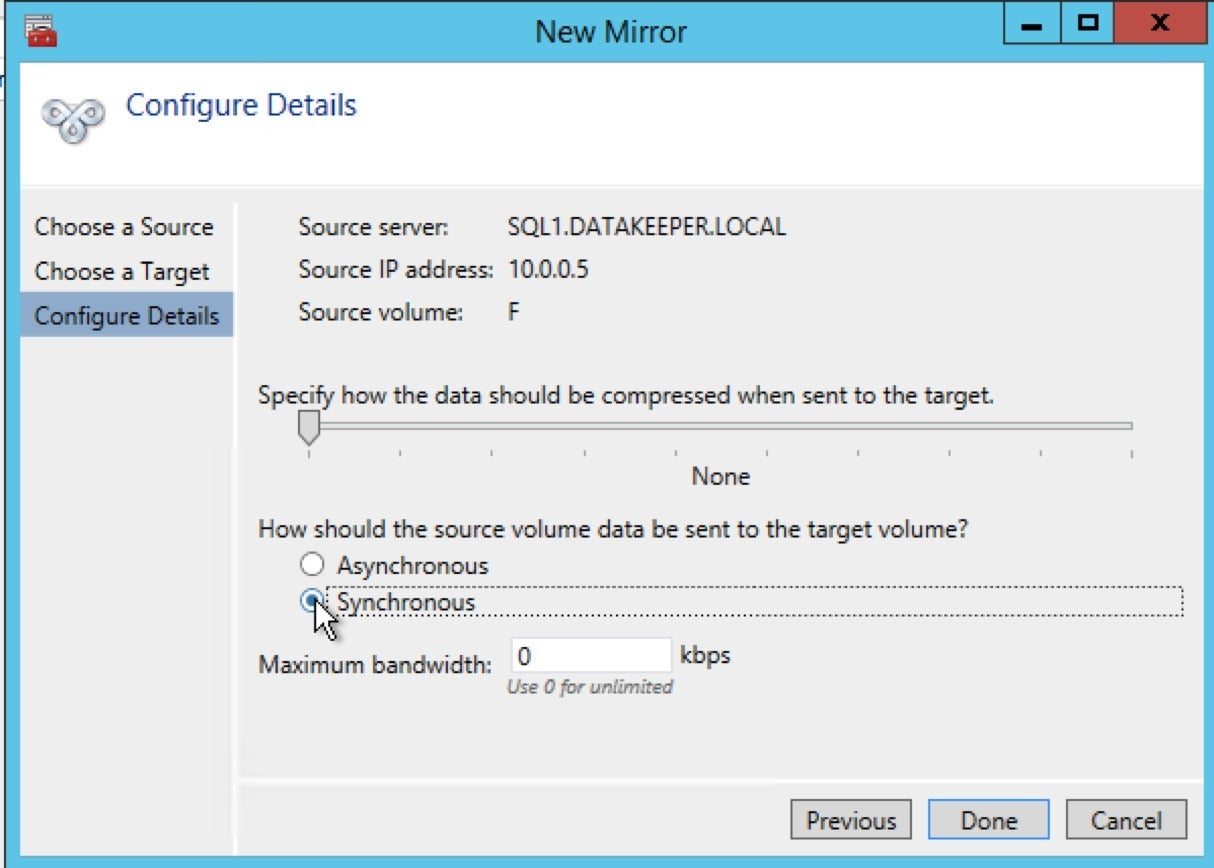 SIOS Technology
SIOS TechnologyHere you can configure levels of data compression during replication as well as the method of replication. For a failover target in the same region, select Synchronous. For a failover target in a distant region, select Asynchronous. Then, click Done. SIOS DataKeeper will create the mirror.
Step 4: Auto-register the new mirror as a cluster resource.
Once the mirror is created, you will be offered the option to register the volume as a cluster resource.
 SIOS Technology
SIOS TechnologyClick Yes to automatically register it.
Once you complete this process, open up the Failover Cluster Manager and look in Disk. You should see the DataKeeper Volume resource in Available Storage. At this point WSFC treats this as if it were a normal cluster disk resource.
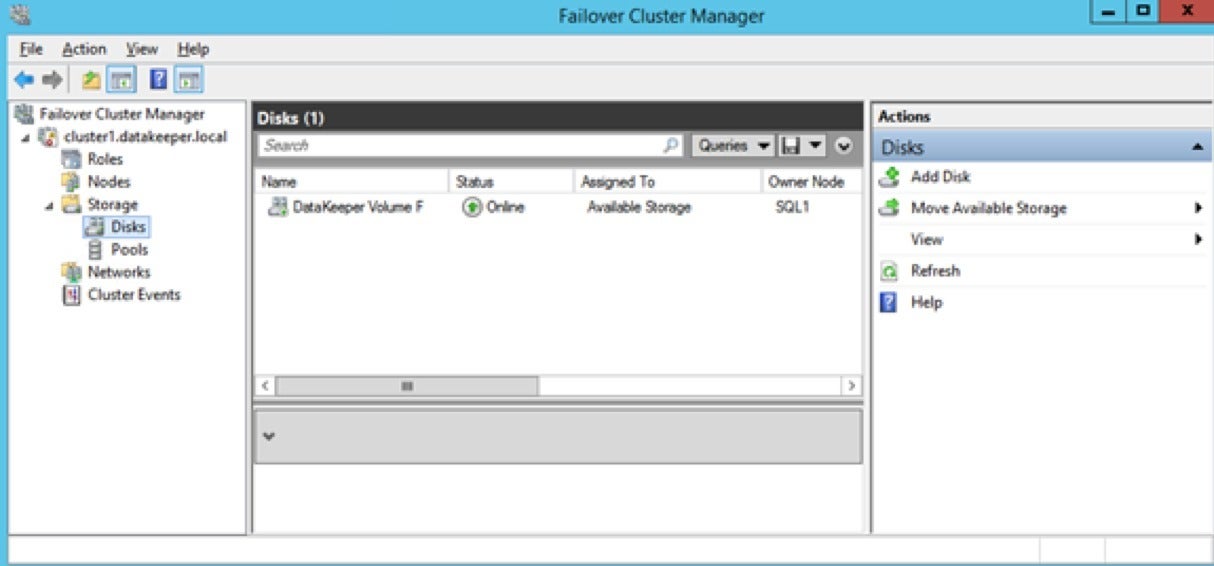 SIOS Technology
SIOS TechnologyAt this point you can return to the instructions in the Google documentation and continue from the point of “Configuring high availability for the SQL Server using FCI.” This will reinstall SQL Server on your VMs but rely on the multi data center storage configuration you have just created using SIOS DataKeeper. You’ll configure the cluster for health checker per the instructions in the GCP documentation and then test the failover scenario using those same instructions.
The one thing that you’ll notice now, though, is that the limitations section no longer applies. Having configured a SANless Failover Cluster rather than one based on Storage Spaces Direct, you can use any edition of SQL Server. Moreover, each disk in the SANless cluster contains a complete block-level replica of the data, so you gain that 99.99 percent level of availability that you’ve been seeking.
David Bermingham is a high availability expert and eight-year Microsoft MVP, six years as a Cluster MVP and two years as a Cloud and Datacenter Management MVP. David’s work as director at SIOS Technology has him focused on evangelizing Microsoft high availability and disaster recovery solutions and providing hands-on support, training and professional services for cluster implementations. Email David at David.Bermingham@us.sios.com and learn more at us.sios.com and www.ClusteringforMereMortals.com.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.