






The inevitable slowing of Moore’s Law has pushed the computing industry to undergo a paradigm shift from the traditional CPU-only homogeneous computing to heterogeneous computing. With this change, CPUs are complemented by special-purpose, domain-specific computing fabrics. As we’ve seen over time, this is well reflected by the tremendous growth of hybrid-CPU/GPU computing, significant investment on AI/ML processors, wide deployment of SmartNIC, and more recently, the emergence of computational storage drives.
Not surprisingly, as a new entrant into the computing landscape, the computational storage drive sounds quite unfamiliar to most people and many questions naturally arise. What is a computational storage drive? Where should a computational storage drive be used? What kind of computational function or capability should a computational storage drive provide?
Resurgence of a simple and decades-old idea
The essence of computational storage is to empower data storage devices with additional data processing or computing capabilities. Loosely speaking, any data storage device — built on any storage technology, such as flash memory and magnetic recording — that can carry out any data processing tasks beyond its core data storage duty can be called a computational storage drive.
The simple idea of empowering data storage devices with additional computing capability is certainly not new. It can be traced back to more than 20 years ago through the intelligent memory (IRAM) and intelligent disks (IDISKs) papers from Professor David Patterson’s group at UC Berkeley around 1997. Fundamentally, computational storage complements host CPUs to form a heterogeneous computing platform.
Computational storage even stems back to when early academic research showed that such a heterogeneous computing platform can significantly improve the performance or energy efficiency for a variety of applications like database, graph processing, and scientific computing. However, the industry chose not to adopt this idea for real world applications simply because previous storage professionals could not justify the investment on such a disruptive concept in the presence of the steady CPU advancement. As a result, this topic has become largely dormant over the past two decades.
Fortunately, this idea recently received a significant resurgence of interest from both academia and industry. It is driven by two grand industrial trends:
- There is a growing consensus that heterogeneous computing must play an increasingly important role as the CMOS technology scaling is slowing down.
- The significant progress of high-speed, solid-state data storage technologies pushes the system bottleneck from data storage to computing.
The concept of computational storage natively matches these two grand trends. Not surprisingly, we have seen a resurgent interest on this topic over the past few years, not only from academia but also, and arguably more importantly, from the industry. Momentum in this space was highlighted when the NVMe standard committee recently commissioned a working group to extend NVMe for supporting computational storage drives, and SNIA (Storage Networking Industry Association) formed a working group on defining the programming model for computational storage drives.
Computational storage in the real world
As data centers have become the cornerstone of modern information technology infrastructure and are responsible for the storage and processing of ever-exploding amounts of data, they are clearly the best place for computational storage drives to start the journey towards real world application. However, the key question here is how computational storage drives can best serve the needs of data centers.
Data centers prioritize on cost savings, and their hardware TCO (total cost of ownership) can only be reduced via two paths: cheaper hardware manufacturing, and higher hardware utilization. The slow-down of technology scaling has forced data centers to increasingly rely on the second path, which naturally leads to the current trend towards compute and storage disaggregation. Despite the absence of the term “computation” from their job description, storage nodes in disaggregated infrastructure can be responsible for a wide range of heavy-duty computational tasks:
- Storage-centric computation: Cost savings demand the pervasive use of at-rest data compression in storage nodes. Lossless data compression is well known for its significant CPU overhead, mainly because of the high CPU cache miss rate caused by the randomness in compression data flow. Meanwhile, storage nodes must ensure at-rest data encryption too. Moreover, data deduplication and RAID or erasure coding can also be on the task list of storage nodes. All of these storage-centric tasks demand a significant amount of computing power.
- Network-traffic-alleviating computation: Disaggregated infrastructure imposes a variety of application-level computation tasks onto storage nodes in order to greatly alleviate the burden on inter-node networks. In particular, compute nodes could off-load certain low-level data processing functions like projection, selection, filtering, and aggregation to storage nodes in order to largely reduce the amount of data that must be transferred back to compute nodes.
To reduce storage node cost, it is necessary to off-load heavy computation loads from CPUs. Compared to off-loading computations to separate standalone PCIe accelerators for conventional design practice, directly migrating computation into each storage drive is a much more scalable solution. In addition, it minimizes data traffic over memory/PCIe channels, and avoids data computation and data transfer hotspots.
The need for CPU off-loading naturally calls for computational storage drives. Apparently, storage-centric computation tasks (in particular compression and encryption) are the most convenient pickings, or low-hanging fruit, for computational storage drives. Their computation-intensive and fixed-function nature renders compression or encryption perfectly suited for being implemented as customized hardware engines inside computational storage drives.
Moving beyond storage-centric computation, computational storage drives could further assist storage nodes to perform computation tasks that aim to alleviate the inter-node network data traffic. The computation tasks in this category are application-dependent and hence require a programmable computing fabric (e.g., ARM/RISC-V cores or even FPGA) inside computational storage drives.
It is clear that computation and storage inside computational storage drives must cohesively and seamlessly work together in order to provide the best possible end-to-end computational storage service. In the presence of continuous improvement of host-side PCIe and memory bandwidth, tight integration of computation and storage becomes even more important for computational storage drives. Therefore, it is necessary to integrate computing fabric and storage media control fabric into one chip.
Architecting computational storage drives
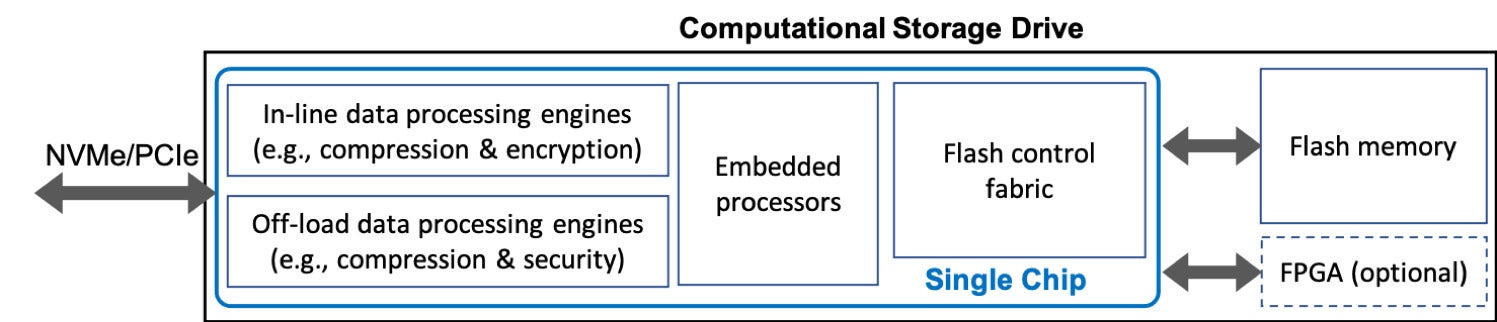
At a glance, a commercially viable computational storage drive should have the architecture as illustrated in Figure 1 below. A single chip integrates flash memory control and computing fabrics that are connected via a high-bandwidth on-chip bus, and the flash memory control fabric can serve flash access requests from both the host and the computing fabric.
Given the universal at-rest compression and encryption in data centers, computational storage drives must own compression and encryption in order to further assist any application-level computation tasks. Therefore, computational storage drives must strive to provide the best-in-class support of compression and encryption, ideally in both in-line and off-loaded modes, as illustrated in Figure 1.
 ScaleFlux
ScaleFlux
Figure 1: Architecture of computational storage drives for data centers.
For the in-line compression/encryption, computational storage drives implement compression and encryption directly along the storage IO path, being transparent to the host. For each write IO request, data go through the pipelined compression → encryption → write-to-flash path; for each read IO request, data go through the pipelined read-from-flash → decryption → decompression path. Such in-line data processing minimizes the latency overhead induced by compression/encryption, which is highly desirable for latency-sensitive applications such as relational databases.
Moreover, computational storage drives may integrate additional compression and security hardware engines to provide off-loading service through well-defined APIs. Security engines could include various modules such as root-of-trust, random number generator, and multi-mode private/public key ciphers. The embedded processors are responsible for assisting host CPUs on implementing various network-traffic-alleviating functions.
Finally, it’s key to remember that a good computational storage drive must first be a good storage device. Its IO performance must be at least comparable to that of a normal storage drive. Without a solid foundation of storage, computation becomes practically irrelevant and meaningless.
Following the above intuitive reasoning and the naturally derived architecture, ScaleFlux (a Silicon Valley startup company) has successfully launched the world’s first computational storage drives for data centers. Its products are being deployed in hyperscale and webscale data centers worldwide, helping data center operators to reduce the system TCO in two ways:
- Storage node cost reduction: The CPU load reduction enabled by ScaleFlux’s computational storage drives allows storage nodes to reduce the CPU cost. Therefore, without changing the compute/storage load on each storage node, one can directly deploy computational storage drives to reduce the per-node CPU and storage cost.
- Storage node consolidation: One could leverage the CPU load reduction and intra-node data traffic reduction to consolidate the workloads of multiple storage nodes into one storage node. Meanwhile, the storage cost reduction enabled by computational storage drives largely increases the per-drive storage density/capacity, which further supports storage node consolidation.
Looking into the future
The inevitable paradigm shift towards heterogeneous and domain-specific computing opens a wide door for opportunities and innovations. Natively echoing the wisdom of moving computation closer to data, computational storage drives are destined to become an indispensable component in future computing infrastructure. Driven by the industry-wide standardization efforts (e.g., NVMe and SNIA), this emerging area is being actively pursued by more and more companies. It will be exciting to see how this new disruptive technology progresses and evolves over the next few years.
Tong Zhang is co-founder and chief scientist at ScaleFlux.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.