






Kubernetes is the most prominent technology in modern microservices. It is designed to make managing microservices clusters of containerized applications simpler and more automated. Beneath this simple notion is a world of complexity. This article gives you a detailed conceptual understanding of how this central technology works.
One helpful way to think about Kubernetes is as a distributed operating system for containers. It provides the tools and commands necessary for orchestrating the interaction and scaling of containers (most commonly Docker containers) and the infrastructure containers run on. A general tool designed to work for a wide range of scenarios, Kubernetes is a very flexible system—and very complex.
Read on for an understanding of the architecture that makes Kubernetes tick.
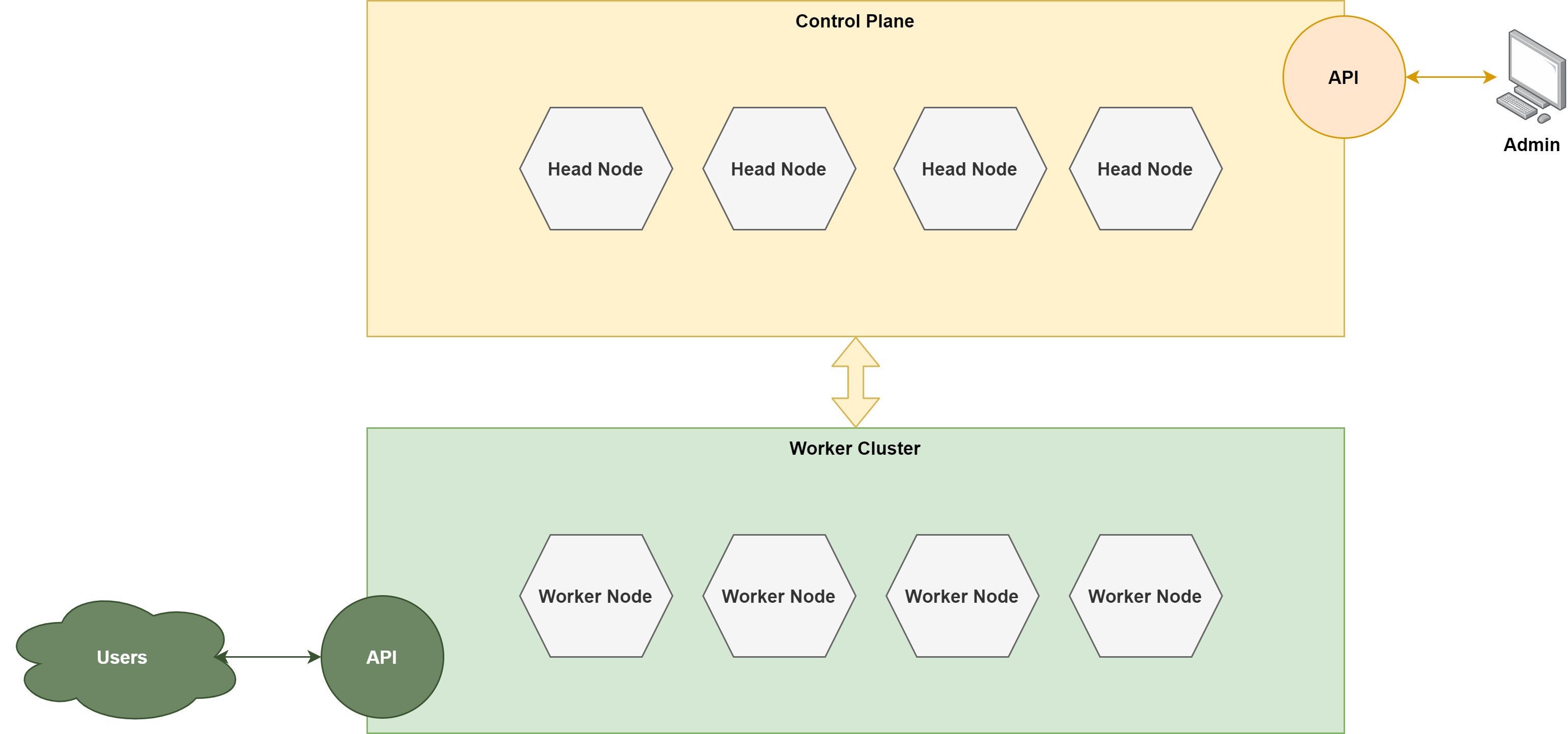
Kubernetes worker nodes and control plane
There are two aspects to Kubernetes: the worker nodes and the control plane. The worker nodes are where the actual containerized applications exist along with the necessary Kubernetes tooling. The control plane is where the tools for managing this cluster lives. Figure 1 has a high level look at this architecture.
Figure 1. Kubernetes worker nodes and control plane
 IDG
IDG
Figure 1.
As you can see in Figure 1, the architecture is split between worker nodes and head nodes responsible for running workloads and running management tools, respectively.
Nodes in both cases are machines, virtual or actual.
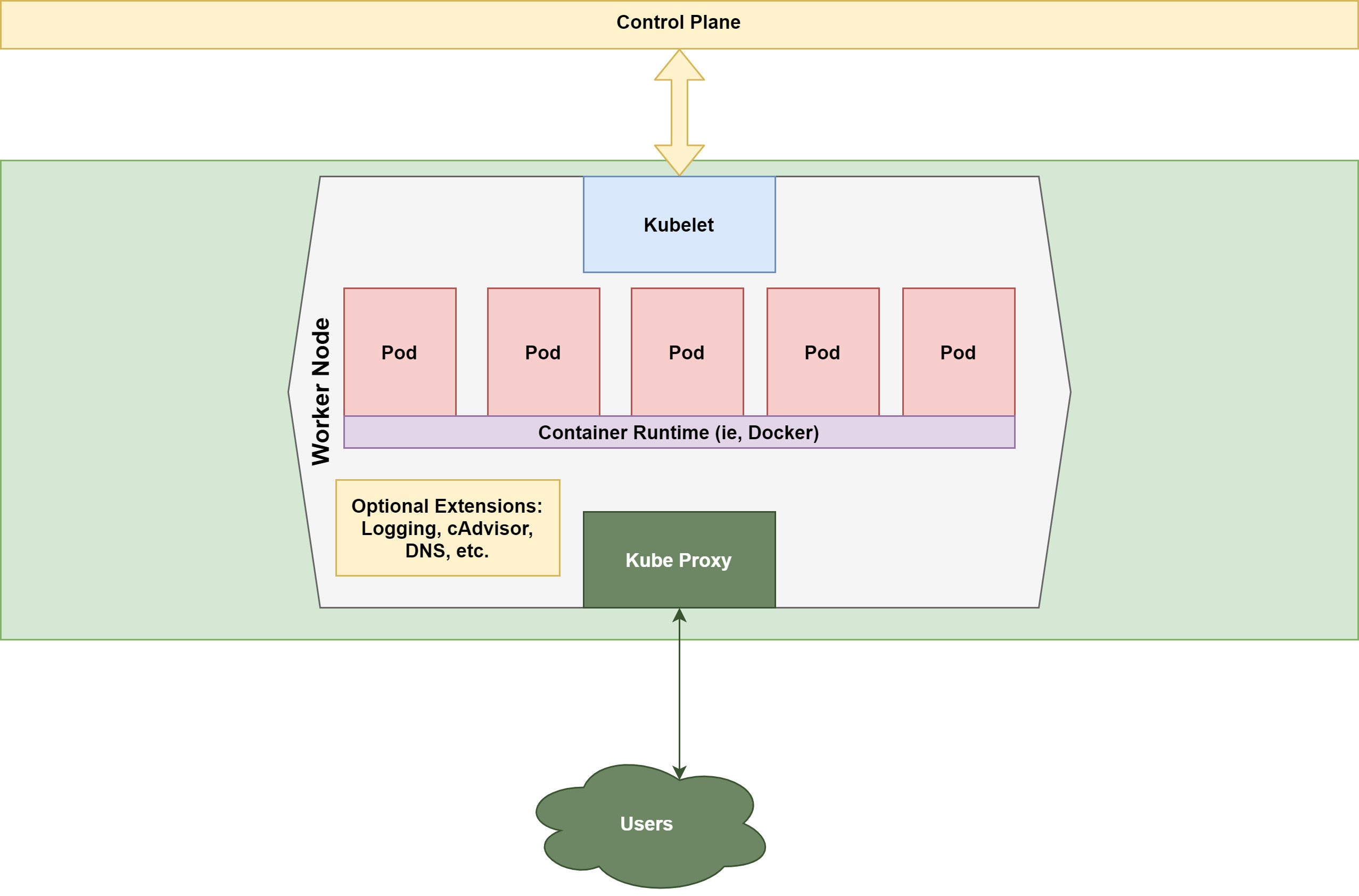
Kubernetes worker node components
Figure 2 illustrates the essential elements of a Kubernetes worker node. Let’s take a look at each components in turn.
Figure 2. Kubernetes worker node detail
 IDG
IDG
Figure 2.
Kubelet
A kubelet is a “small” program running on the worker node responsible for negotiating between the control plane and the node. Its core purpose is to enforce the directives coming from the head node cluster upon the pods, and report back the current condition of the worker loads.
Kube Proxy
The kube proxy is responsible for enforcing network rules on the node and allowing for traffic to and from the node.
The kube proxy is distinct from ingress, which operates at the cluster level and defines rules for the network routes into the cluster.
Pods
Pods are the discrete unit of work on the node. Pods are the level of replication. They are an abstraction that wraps one or multiple containerized applications. Pods provide a way to logically group and isolate containers that run together, while still allowing inter-pod communication on the same machine. The relationship between containers and pods is controlled by Kubernetes deployment descriptors.
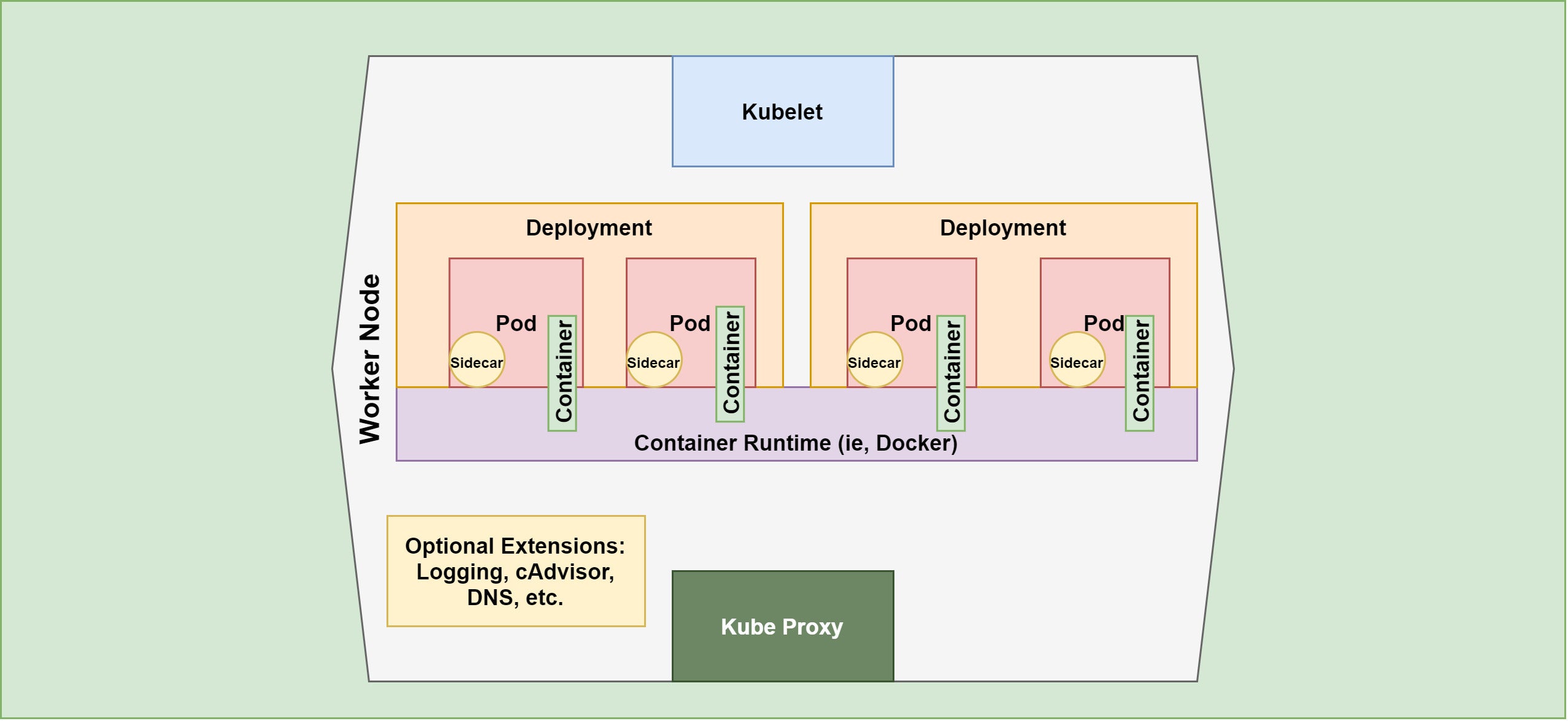
Deployments and ReplicaSets
Pods are usually configured and deployed as part of a ReplicaSet. A ReplicaSet defines the desired runtime characteristics of the pod, and causes Kubernetes to work to maintain that state. ReplicaSets are usually defined by a Deployment, which defines both the ReplicaSet parameters and the strategy to use (i.e., whether pods are updated or recreated) when managing the cluster.
Sidecars
At the pod level, extra functionality is enabled via sidecar add-ons. Sidecars handle tasks like pod-level logging and stats gathering.
Figure 3 provides a more detailed look at the pods in a worker node.
Figure 3. Kubernetes pod detail
 IDG
IDG
Figure 3.
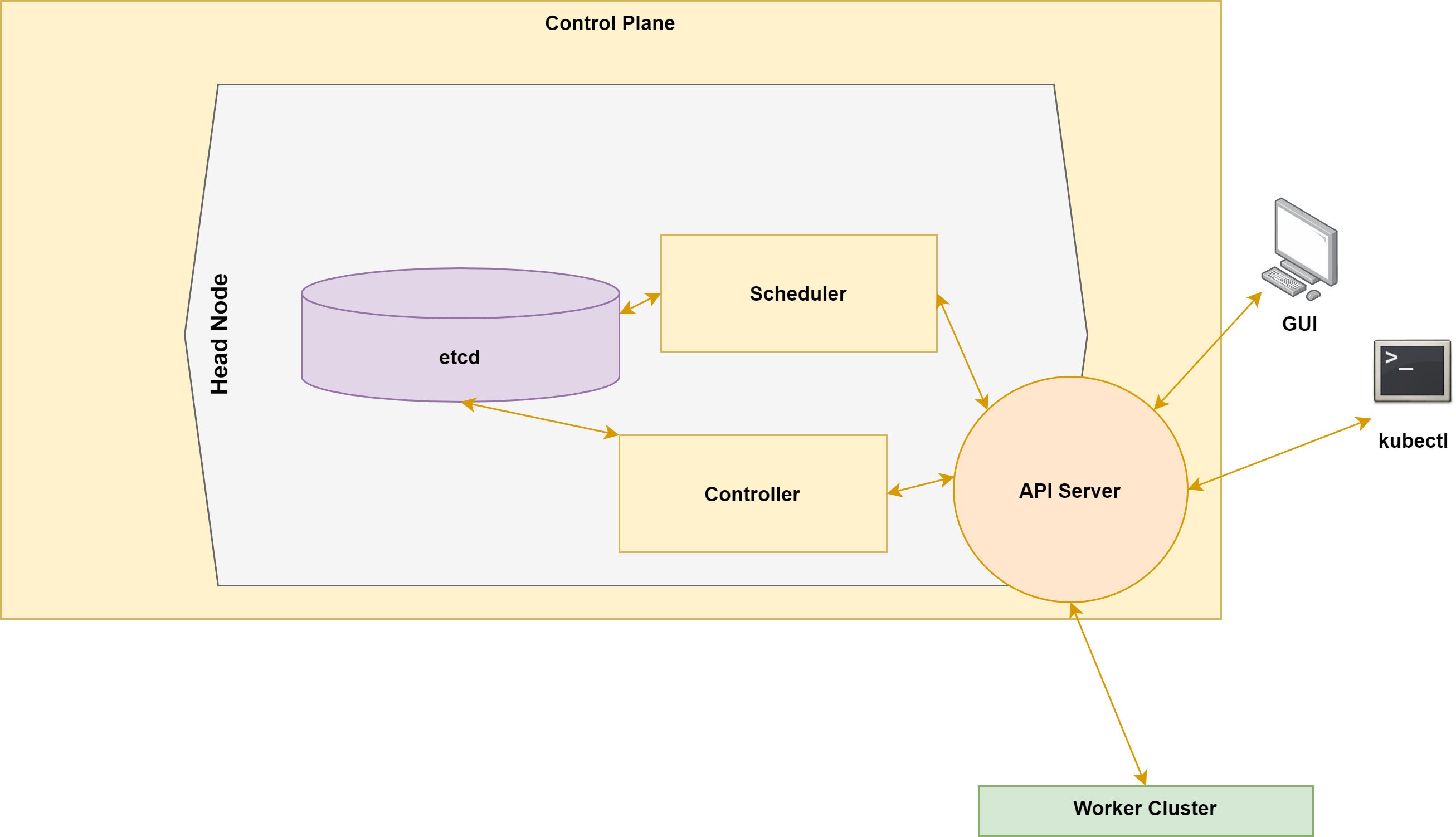
Kubernetes control plane
So far we’ve focused on understanding the worker side of things. Let’s turn now to the controller side, and gain an understanding of how Kubernetes operates to control the operation of the cluster.
Figure 4 offers a detailed look at the head node components.
Figure 4. Kubernetes head node detail
 IDG
IDG
Figure 4.
Etcd
The simplest-to-understand component is etcd (pronounced “et-cee-dee”). Etcd is a distributed object store that acts as the database of record for the configuration and state of the entire cluster.
API server
As is clear from Figure 4, the API server is the central communication mechanism for the cluster. It brokers the interaction between the control plane, the worker nodes, and the administrators as they apply configuration changes via the Kubernetes command line tools (like kubectl) or other UI.
Scheduler
The scheduler is responsible for identifying the node that pods will run on. The details of how this is determined vary based on the characteristics of the pods and the existing state of the available nodes. The strategy for how the scheduler approaches this decision making can be tuned all the way up to the ability to write custom schedulers. The scheduler interacts with the API server in performing its work.
Controller
The controller component is responsible for keeping the cluster in the desired state as configured, and moving it towards that state when it drifts away from it. The controller acts as a kind of thermostat that specifies a desired state and then works to maintain it.
In Kubernetes terminology, you create an object, which is a persistent entity logged within etcd. The object is a record for how things should be. The controller then acts to ensure that the object has the desired specs, or properties.
As an example, a ReplicaSet (discussed above) defines how many pods should be running based on usage criteria. The ReplicaSet is the object, and the specified pod count is the spec. The actual state of the cluster with respect to that ReplicaSet is the status. The controller receives consistent reports from the cluster as to this status, and takes action to bring the status into agreement with the specs by creating or destroying pods.
Container image repository
A final component to be aware of is the image repository (also called an image registry). This component exists outside the cluster and is accessed by administrators and the control plane to download required container definitions. Registries are hosted by a variety of organizations including Docker Hub and can be public or private. The major cloud providers all offer managed repositories for enterprise use.
Kubernetes rules containers
You now have an understanding of Kubernetes architecture and how Kubernetes works to achieve its goal. It is not a simple system, but that is because deploying, managing, and scaling container-based applications is not a simple goal. Kubernetes is highly configurable and flexible enough to deal with the wide range of container-based application scenarios encountered in the wild.
Kubernetes is the preeminent technology in the current approaches to software architecture. Consequently, knowledge of Kubernetes will be essential for anyone with an interest in devops, containers, cloud native applications, and microservices architecture.